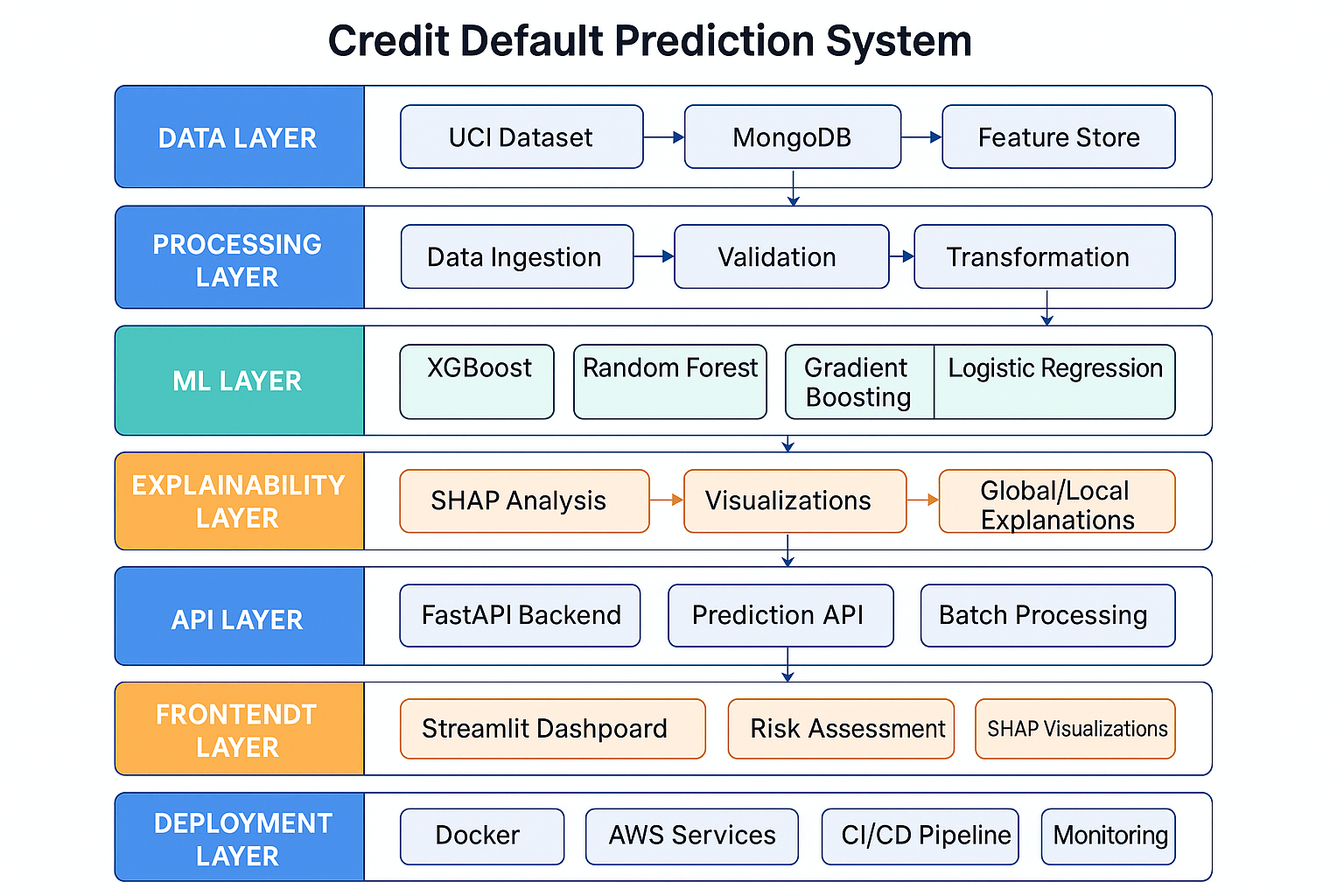
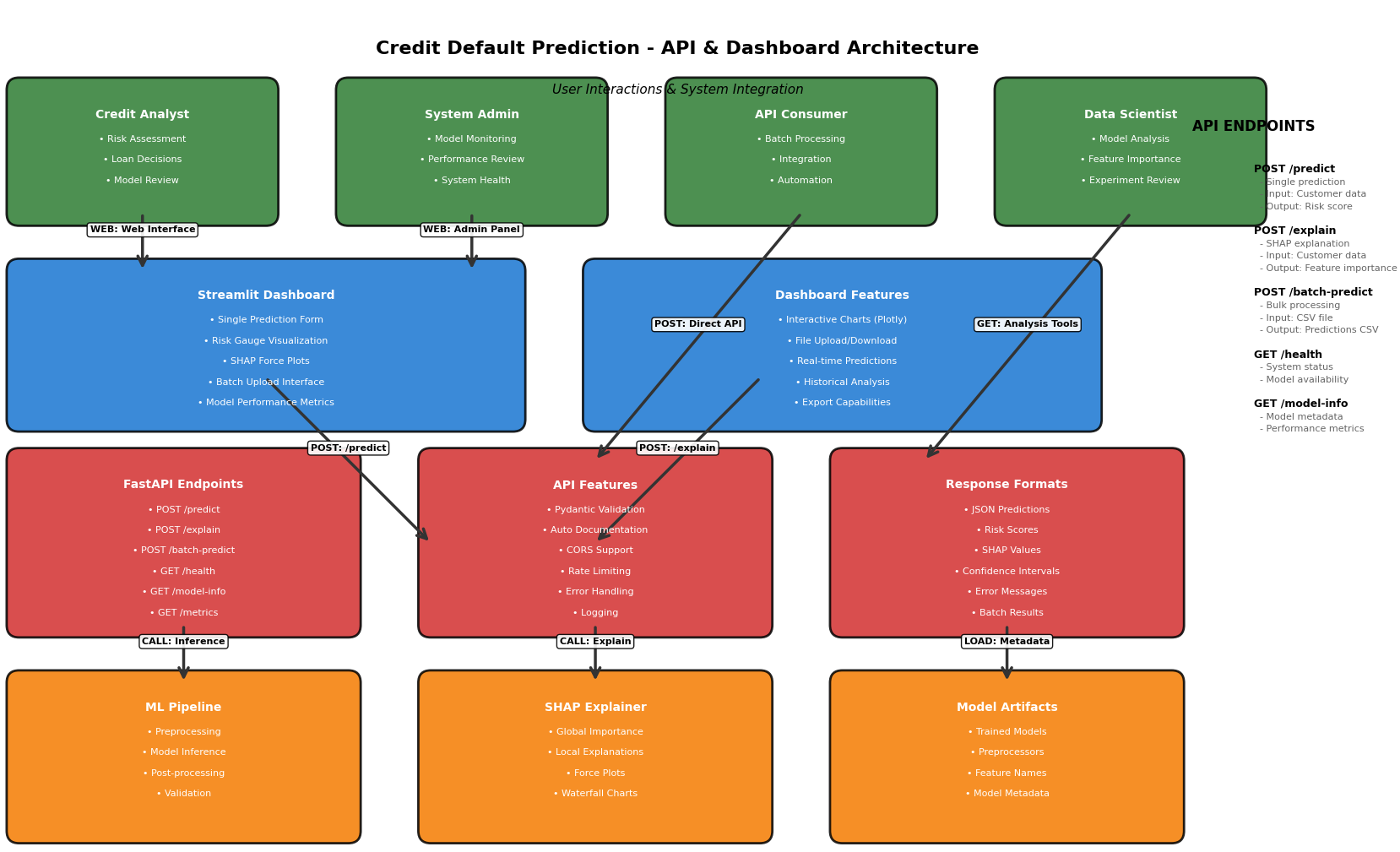
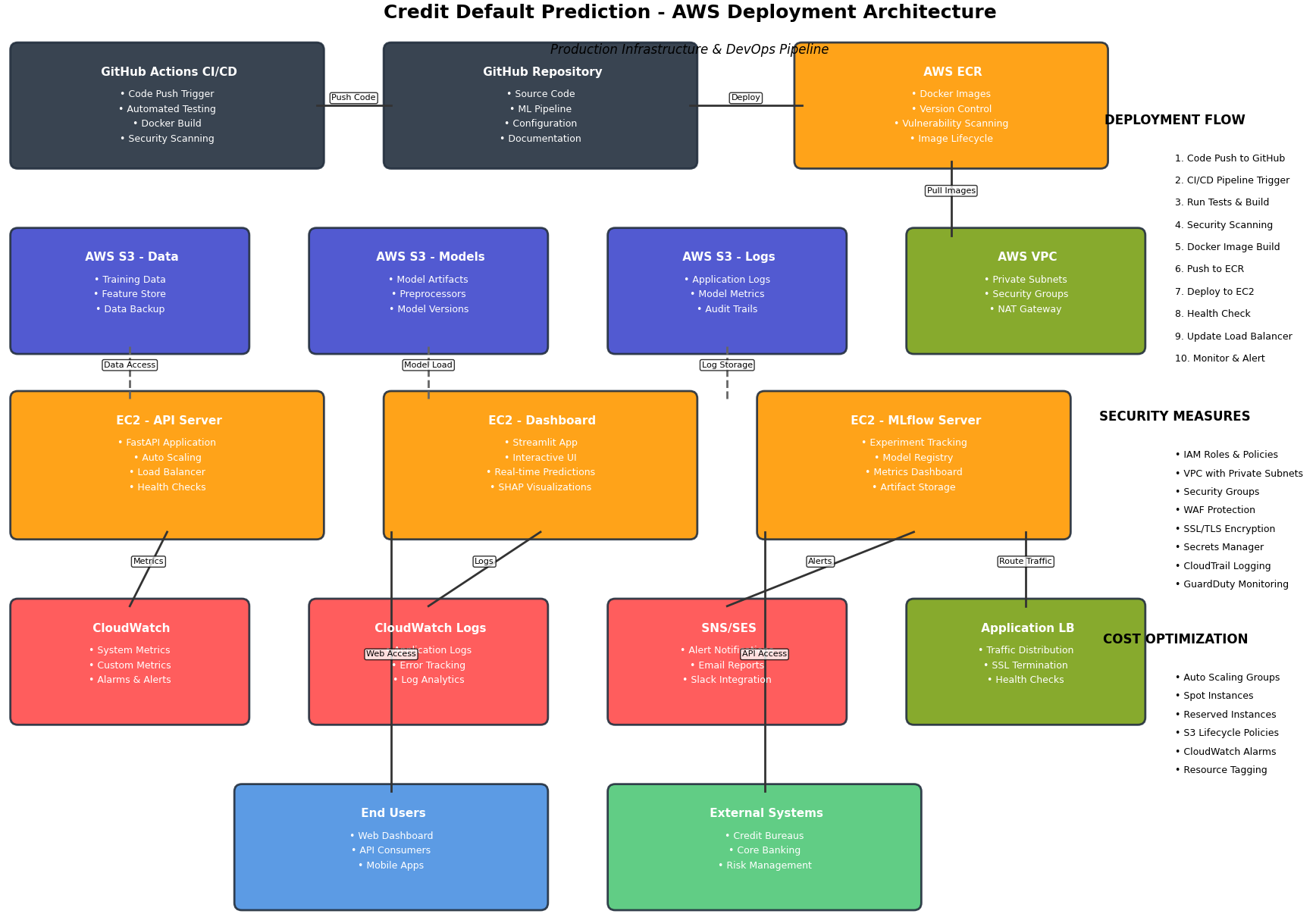
Explainable AI with SHAP
Understanding SHAP in Credit Risk
SHAP explanations help us understand which features to focus on to understand why credit default happened. For example, if a customer has high credit utilization (90% of credit limit) and recent payment delays, SHAP will show exactly how much each factor contributes to the high default risk prediction.
Business Example
Why Explainability Matters
- Regulatory compliance (Fair Credit Reporting Act)
- Customer trust and transparency
- Business insight for strategy improvement
- Model debugging and bias detection
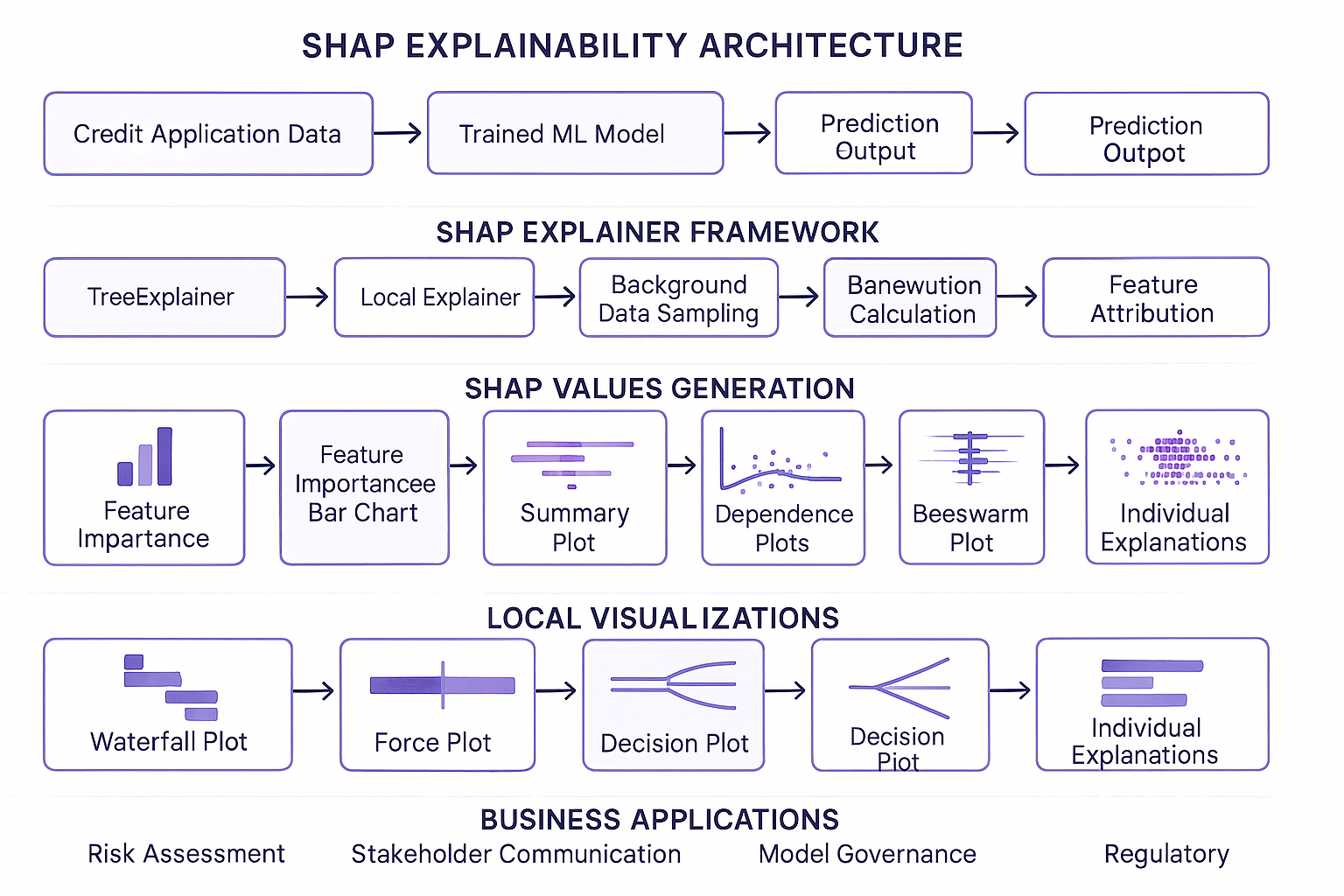
SHAP Implementation
Comprehensive SHAP integration providing both global feature importance and local explanations for individual predictions.
# SHAP Explainer Implementation
import shap
import numpy as np
import pandas as pd
class CreditDefaultSHAPExplainer:
def __init__(self, model, X_train, feature_names):
self.model = model
self.feature_names = feature_names
self.explainer = shap.TreeExplainer(model)
self.shap_values = self.explainer.shap_values(X_train)
def get_global_importance(self):
"""Global feature importance across all predictions"""
importance = np.abs(self.shap_values).mean(0)
return pd.DataFrame({
'feature': self.feature_names,
'importance': importance
}).sort_values('importance', ascending=False)
def explain_prediction(self, instance):
"""Local explanation for single prediction"""
shap_values = self.explainer.shap_values(instance.reshape(1, -1))
return shap_values[0]
Global Explanations
Understand overall model behavior and feature importance across the entire dataset. Shows which features are most influential for default prediction in general.
- Feature importance ranking
- SHAP summary plots
- Dependence plots
Local Explanations
Explain individual predictions by showing exactly how each feature contributed to the specific customer's risk assessment.
- Individual prediction breakdown
- SHAP waterfall plots
- Force plots for decision factors
Feature Importance Visualization
Add Feature Importance Plot Image URL Here
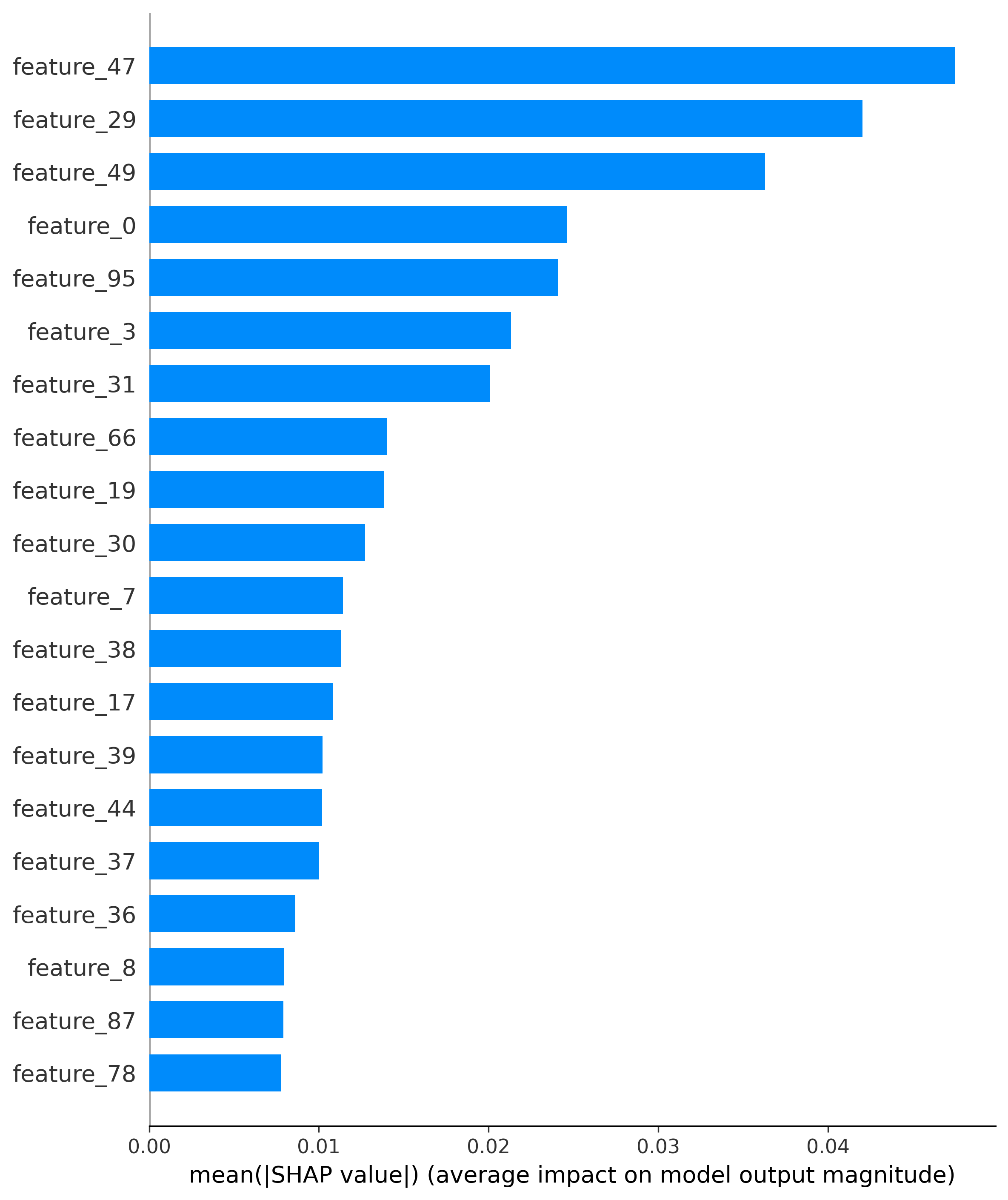
This chart shows the most important features for credit default prediction, with payment history and credit utilization being top predictors.
SHAP Summary Plot
Add SHAP Summary Plot Image URL Here
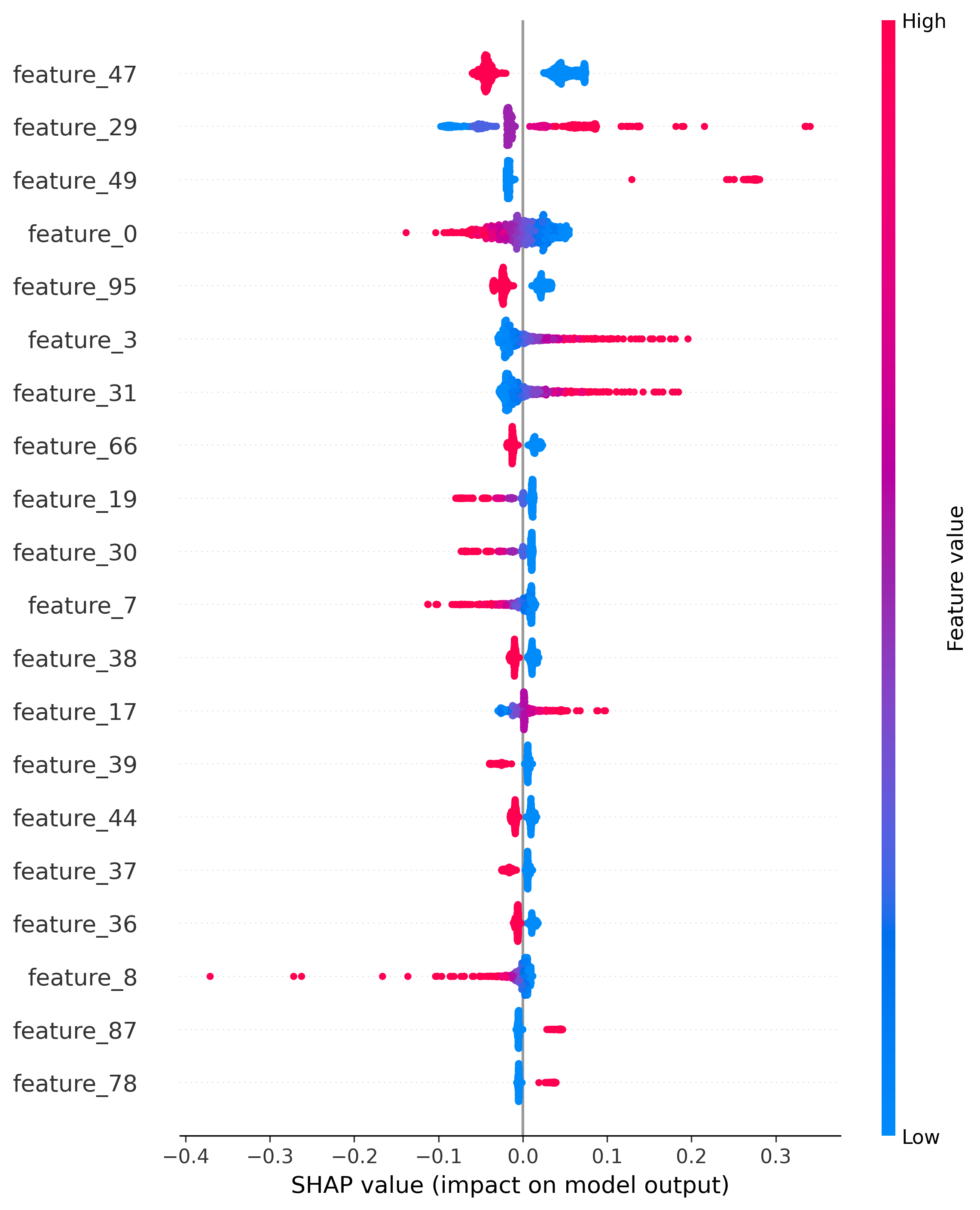
Summary plot shows the distribution of SHAP values for each feature, indicating both positive and negative contributions to default risk.